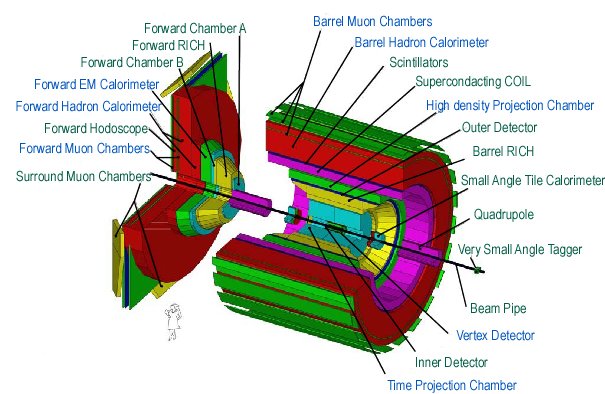
A schematic diagram of the DELPHI detector. The detector components named in blue are components that you will use in the projects.
DELPHI stands for DEtector for Lepton, Photon, and Hadron Identification, which gives a pretty good idea of what the detector does. Lepton is the collective noun for electrons, muons, taus and neutrinos. It comes from a Greek word meaning 'small'. Photons are the particles that carry the electromagnetic interaction, and hadrons are all particles that feel the strong interaction. It's origin is also a Greek word, this time meaning 'thick'.
The DELPHI detector measured about 10 metres in diameter and was 10 metres long, it weighed about 3500 tons. DELPHI's design and construction took seven years, and the detector collected data for over a decade. DELPHI consisted of three parts, a cylindrical barrel and two so-called endcaps closing the ends of the cylinder, each of these was mounted on rails so that it could be moved in and out for maintenance.
The DELPHI detector surrounded the LEP accelerator's beam pipe at one of the places where electrons and positrons collided. Collisions took place in the centre of the barrel section, and whatever direction particles emerged, they had to pass through either the barrel or an endcap. Each of the three sections consisted of many different parts, called subdetectors, of which there were 19 in total.
The aim with the whole DELPHI set-up was to :
Particle identification is a job for all the subdetectors working together since each gives different hints about the identity of the particles that pass through it. The momenta of the charged particles are calculated by measuring the curvature of the paths the particles move along in the magnetic field, as seen by the tracking subdetectors. The direction of the curvature with respect to the magnetic field also indicates whether a particle is positively charged or negatively charged.
A schematic diagram of the DELPHI detector. The detector components named in blue are components that you will use in the projects.
Tracking in DELPHI is mainly performed by the exotically-named Time Projection Chamber (TPC), assisted by a very precise tracking detector close to the collision point called the Vertex Detector (VD). The Inner Detector (ID), chambers in the end-caps called Forward Chamber A and B (FCA, FCB), and the Muon system (MUB, MUF, MUS) also take part in the tracking.
The TPC is a cylindrical volume filled with gas in which the charged particles ionize the gas along their trajectories. An electric field caused the liberated electrons to drift towards one end of the volume where they are detected. The end wall is divided in such a way that a two-dimensional picture of the ionization, corresponding to the tracks of passing particles, can be reconstructed. The accuracy on the two coordinates thus obtained is around a quarter of a millimetre. The third coordinate is extracted by measuring the arrival time of the ionization and projecting back to work out where the particle must have passed, hence the name Time Projection Chamber. Since the drift speed of the ionization is known accurately, this gives the third coordinate to a precision of just under a millimetre. In this way a three-dimensional picture of the event can be reconstructed in the TPC.
Calorimetry, energy measurement, in DELPHI is performed by two types of calorimeters called electromagnetic and hadronic. The electromagnetic calorimeters measure the energies of particles interacting via the electromagnetic interaction: electrons, positrons and photons. The hadronic calorimeters measure the energies of particles interacting mainly via the strong interaction. These are particles made up of quarks, collectively known as hadrons.
Both types of calorimeters rely on the same basic principle: particles interact with a dense medium and give rise to a cascade of secondary particles. The dense medium is thick enough to stop even particles with the highest possible energies at LEP, with the exception of muons and neutrinos, which we will come back to later. In both calorimeters, the dense medium is interleaved with an active medium where the shower of particles deposits a fraction of its energy. By measuring the total energy deposited in the active medium the energy of the initial particle can be calculated.
Since the electromagnetic interaction is very different from the strong interaction the best material for the dense medium is quite different for the two different kinds of calorimeter. Lead makes a good dense medium for building an electromagnetic calorimeter. It can absorb electromagnetic particles in a relatively compact volume whilst strongly interacting particles punch their way through to the hadronic calorimeter. In DELPHI, iron was chosen for the dense medium of the hadronic calorimeter.
DELPHI's electromagnetic calorimeters are called the High-density Projection Chamber, HPC, and the Forward ElectroMagnetic Calorimeter, FEMC. The HAdron Calorimeter is simply known as the HAC.
Particle identification is performed by combining information from several subdetectors. To identify, for instance:

The imprints of different particle types in the different layers of a particle detector.

The DELPHI Vertex Detector allows the decay point of very short-lived particles to be pinpointed, giving an indication of the particle's lifetime.
